Running Llama Aligned DeepSeek R1 on your own computer using a GPU from AMD, NVIDIA or Intel with Vulkan drivers.
This article is going to show you how to run the Llama aligned DeepSeek R1 Distil models on your own computer using a GPU from AMD, NVIDIA or Intel with Vulkan drivers (i.e. the regular gaming drivers). If you want to use just your CPU, use Apple’s Neural Engine or get the best performance from a NVIDIA GPU (or multiple GPUs) by using Cuda, see the other versions of this article here.
KoboldCPP is an excellent open source program that provides you with a Graphical User Interface to interact with LLMs, for the developers amongst you there is also an API using the familiar OpenAI format.
Blue Beck’s Llama Aligned DeepSeek R1 Distil models are fine tuned versions of Deep Seek AI's 8B and 70B R1-Distil models that culturally align with Meta’s Llama 3 series in order to be more suitable for public facing deployment in western countries, while retaining the reasoning capabilities the R1 based models are famous for.
Start by downloading the latest KoboldCPP for your operating system from the downloads page here, Windows users should choose “koboldcpp_nocuda.exe” and most Linux users should choose “koboldcpp-linux-x64-nocuda”.
If you want to use an Intel Mac with an AMD GPU, the easiest route will be to use the Windows version in Boot Camp, or boot from live Linux USB media then use the Linux version.
Most people should start with the 4bit 8B version of the model, which you can download from here.
Once you've tried this and have it working there is more information in the notes at the bottom of the article for those of you with enough VRAM to try the other versions.
Once you have downloaded the model and KoboldCPP, it is time to get started.
You should satisfy yourself that the KoboldCPP executable that you downloaded from GitHub is safe (i.e. free from malware), here is one way to do this. Deciding to run the executable on your computer is your own responsibility and we in no way accept any liability for any consequences.
Depending on your system, you may need to grant KoboldCPP permission to run in your Operating System.
When KoboldCPP starts, you will see a menu like this.
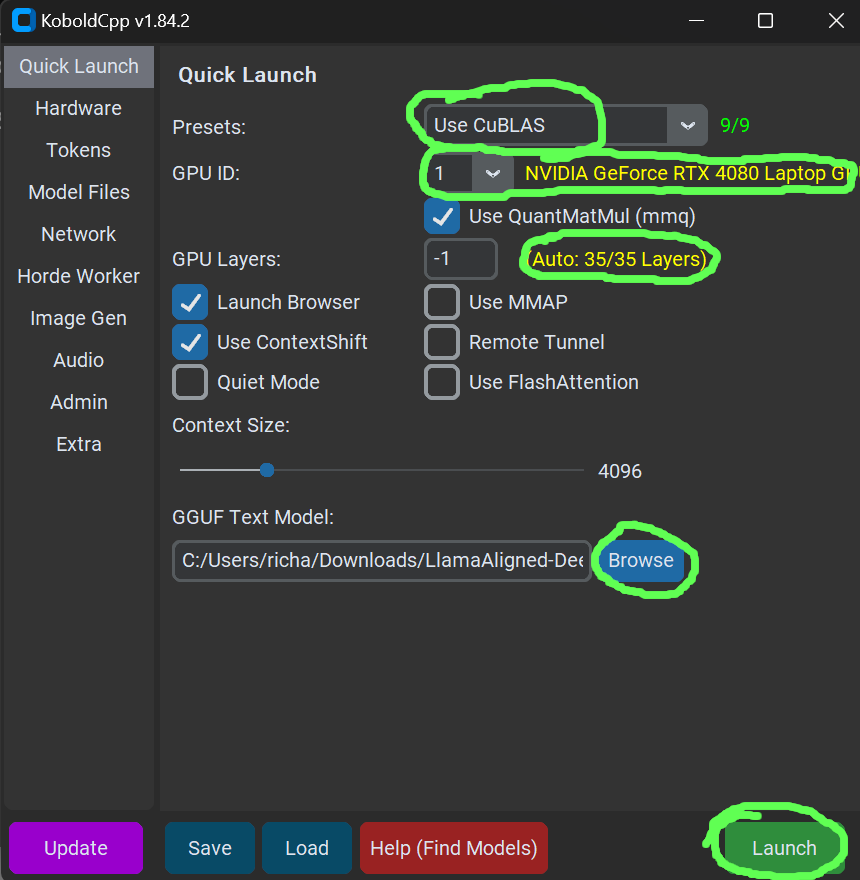
Ensure that for "Presets" the option "Use Vulkan" is selected, and that after the dropdown for "GPU ID" is a description matching the GPU you want to use.
Click the “Browse” button under where it says “GGUF Text Model”, then select the model file you downloaded, i.e. LlamaAligned-DeepSeekR1-Distil-8b.Q4_K_M.gguf
"GPU Layers" should be set to -1 (for auto), and the yellow text after it should indicate how many of the models layers will use the GPU, ideally this will be all of them, otherwise you will take a big performance hit.
In the screenshot above, 35 of 35 (i.e. all of the) layers will be loaded on to the GPU, which is what we want.
If you are seeing less than all of the layers will be loaded on the GPU (i.e. if it said 26/35) try to free up video memory or try a smaller model. If you have more than one NVIDIA GPU and are OK with installing Cuda, try following this version of the article instead.
You can now click Launch in the bottom right hand corner, which should open your web browser pointing to a local URL (something like http://localhost:5001/#) where you should see the user interface for using the LLM.
The first thing you need to do is to click the “Settings” button on the top bar.
This will open a window like the one below. Where it says “Usage Mode” select “Instruct Mode” from the drop down menu, and where it says “Instruct Tag Preset” select “Deepseek V2.5”.
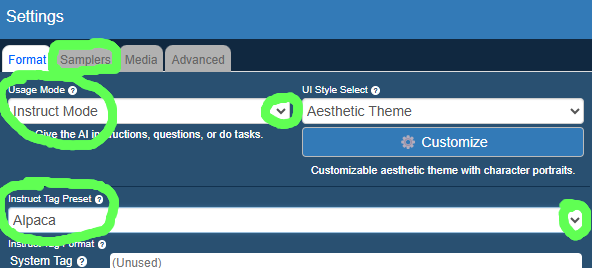
Now change tabs by clicking “Samplers” just under the heading of the settings window.
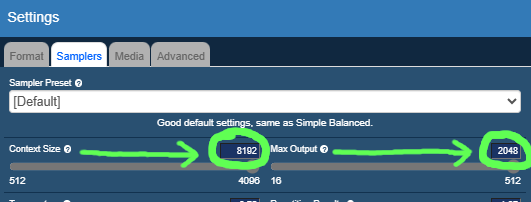
Where it says “Context Size” set the number to 8000 (or higher), and where it says “Max Output” set the number to 2000 (or higher), you will need to change the numbers by clicking on them and editing rather than using the slider bar (DeepSeek R1 based models won’t work well with the smaller number range the slider gives, see the bottom of the article for an explanation).
Once you’ve done this press OK to go back to the main interface.
Everything is now ready and you can go ahead and ask a question, just type in the text box at the bottom and click the send button  like in most chat user interfaces.
like in most chat user interfaces.
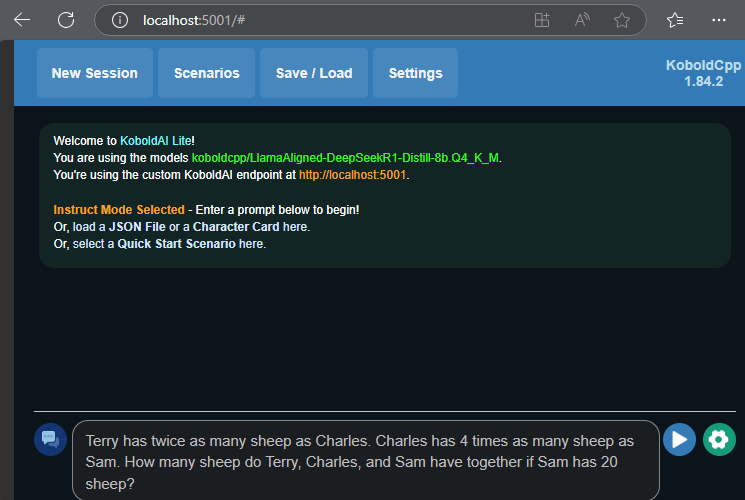
For questions where the model uses an element of reasoning, you will see it output a tag <think> followed by its chain of thought before it gets to its final answer.
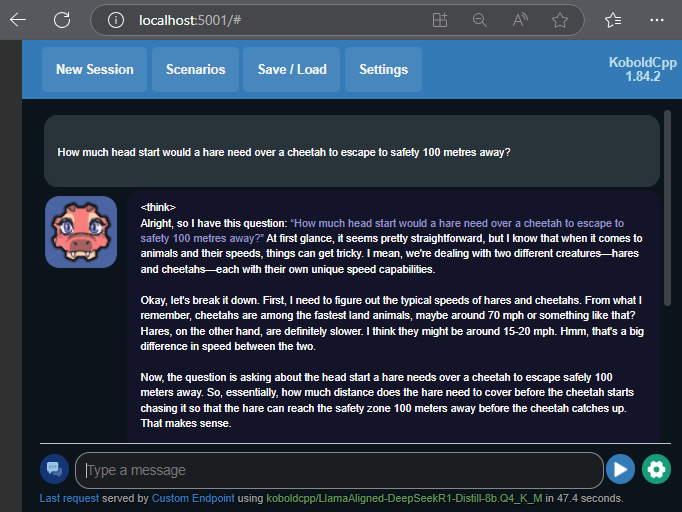
If it stops while it’s still in this process, just press the send button again without typing anything. Once the model has arrived at its final answer, you should see output formatted like this.
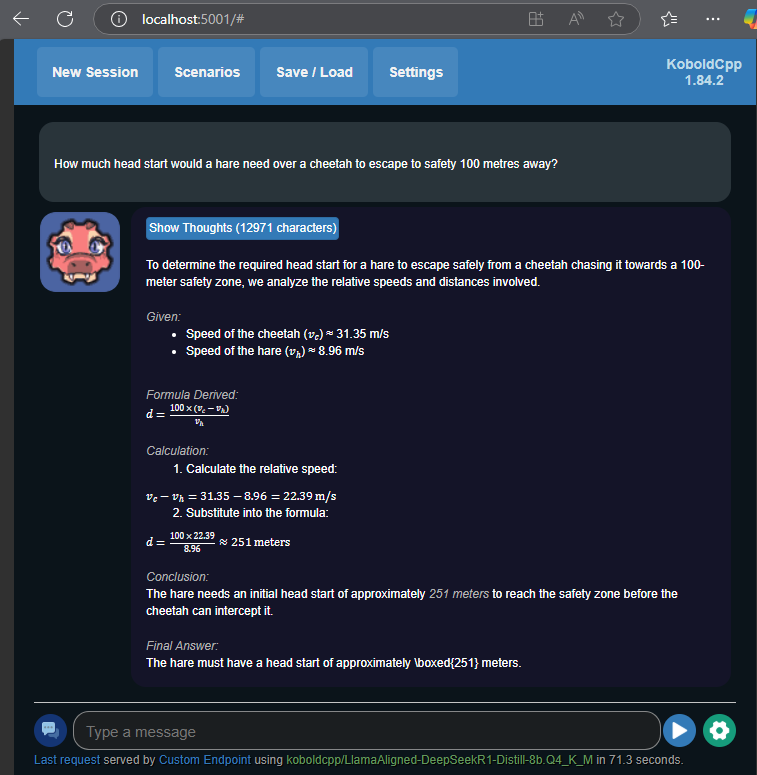
If you want to ask further questions that relate to your previous question just go ahead and type them like in any other chat interface, however if you have a new unrelated question everything will be faster and use less memory if you first click “New Session” in the top left (just press OK on “Really Start A New Session?”).
Additional Notes:
1) The reason for setting “Context Size” and “Max Output” to relatively large numbers is the fact that reasoning models such as those based on DeepSeek R1 output a lengthy chain-of-thought before answering the question. “Context Size” is effectively the maximum size of the whole conversation, and “Max Output” is how much output the model is allowed to generate before KoboldCPP forces it to stop. The default values for these (and even the maximum values of the sliders) are too small to accommodate the full chain of thought output.
2) If you have more VRAM you may wish to try the 8bit 8B version of the model, which can give improved results at a cost of approx 4GB of extra VRAM usage. This can be downloaded from here. Note that even though the model has 8 billion parameters, which at simply 8 bits per parameter would fit in 8GB of VRAM, the model won't fully fit on an 8GB card, this is because not every parameter is quantised to 8 bits so the model is actually a bit larger than 8GB.
3) If you have plenty of VRAM (48GB+) you can try the 70B model. If you have multiple NVIDIA GPUs that add up to 48GB+ of VRAM in total, follow this version of the article. This 70B model is a really powerful model on a different level to the 8B version, far closer in output quality to the largest R1 model or other reasoning models you may have used in the cloud. Download the 4bit version from here, or if you’ve got even more VRAM (80GB+) you can try the 8bit 70B version, which is downloaded in 2 parts (just open part 1 in KoboldCPP as long as part 2 is in the same folder), download part 1 here, and download part 2 here.
4) If you have 32GB+ of VRAM but not enough for the 4bit 70B model above, there is a 3 bit version you can try that may fit in your VRAM. It should be pointed out that this does noticably lose some quality and speed compared to the 4 bit version. The 3bit 70B version of the model can be downloaded from here.